處理i18n國際電話區(qū)號(hào)的代碼實(shí)踐
前言
上周在忙產(chǎn)品的國際化(i18n)的問題 其中一個(gè)很重要的地方就是電話號(hào)碼的國際化(我們以電話號(hào)碼為主賬號(hào)) 電話號(hào)碼有個(gè)很重要的部分就是區(qū)號(hào)
? ?
?
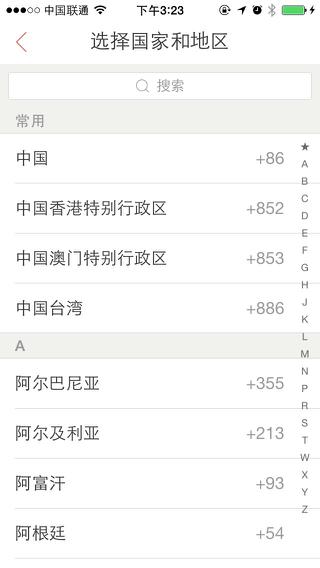
上圖是我們產(chǎn)品的登錄界面 除了常規(guī)的電話號(hào)碼之外 前面還有一個(gè)區(qū)號(hào) 代表這個(gè)電話號(hào)碼所屬的是哪個(gè)國家和地區(qū) 關(guān)于區(qū)號(hào)的概念 可以看一下??維基百科??
看到這里 可能有人奇怪 這有什么難的? 不就是按照列表來展示嗎? 這樣有幾個(gè)問題
- 由于是支持多語言 那么不同的語言環(huán)境的系統(tǒng) 顯示出來的國家名稱是不一樣的 比如“中國” 簡(jiǎn)體中文是“中國” 英文是“China” 韓文是“???????” 其在各個(gè)語言中的顯示排序都是不一樣的
- 如果根據(jù)不同國家和語言來維護(hù)一張這樣的表 工作量太大 一般的公司估計(jì)做不來
所以這個(gè)工作我們就會(huì)放到本地來做 不過iOS已經(jīng)幫我們做了一部分工作了 我們可以根據(jù)??國家代碼??來獲取某個(gè)國家或在當(dāng)前區(qū)域中的本地化名稱
//獲取當(dāng)前l(fā)ocale
NSLocale *locale = [NSLocale currentLocale];
//獲取所有國家的代碼
NSArray *countryArray = [NSLocale ISOCountryCodes];
for (NSString *countryCode in countryArray)
{
//根據(jù)當(dāng)前l(fā)ocale和國家短碼 獲取指定國家的本地化名稱
NSString *localName = [locale displayNameForKey:NSLocaleCountryCode value:countryCode];
}
我們簡(jiǎn)單測(cè)試一下
NSArray *countryArray = [NSLocale ISOCountryCodes];
NSArray *languageArray = @[@"zh_CN",@"en_US",@"ja_JP"];
for ( NSString *languege in languageArray)
{
NSLocale *locale = [[NSLocale alloc] initWithLocaleIdentifier:languege];
for ( int i = 0 ; i < 5 ; ++i )
{
NSString *countryCode = countryArray[i];
NSString *displayName = [locale displayNameForKey:NSLocaleCountryCode value:countryCode];
NSLog(@"%@\t%@\t%@",languege,countryCode,displayName);
}
}
結(jié)果
zh_CN AD 安道爾
zh_CN AE 阿拉伯聯(lián)合酋長(zhǎng)國
zh_CN AF 阿富汗
zh_CN AG 安提瓜和巴布達(dá)
zh_CN AI 安圭拉
en_US AD Andorra
en_US AE United Arab Emirates
en_US AF Afghanistan
en_US AG Antigua and Barbuda
en_US AI Anguilla
ja_JP AD アンドラ
ja_JP AE アラブ首長(zhǎng)國連邦
ja_JP AF アフガニスタン
ja_JP AG アンティグア?バーブーダ
ja_JP AI アンギラ
已經(jīng)介紹完iOS幫我們做的一部分工作了 那么另一部分就得我們自己來了
我們需要有一張 地區(qū)->區(qū)號(hào) 的列表 不過這個(gè)也簡(jiǎn)單 網(wǎng)上一抓一大把 我也是網(wǎng)上找的 文件內(nèi)容如下(diallingcode.json)
[
{
"name": "Afghanistan",
"dial_code": "+93",
"code": "AF"
},
{
"name": "Albania",
"dial_code": "+355",
"code": "AL"
},
...
...
//中間省略
...
...
{
"name": "Virgin Islands, British",
"dial_code": "+1 284",
"code": "VG"
},
{
"name": "Virgin Islands, U.S.",
"dial_code": "+1 340",
"code": "VI"
}
]
維護(hù)這樣一張表就很簡(jiǎn)單了我們可以存在本地 也可以放在服務(wù)器(“name”字段其實(shí)是不必須的 只是為了好看)
研究
我們暫時(shí)先把代碼放一放 來看一看其他產(chǎn)品是怎么做的
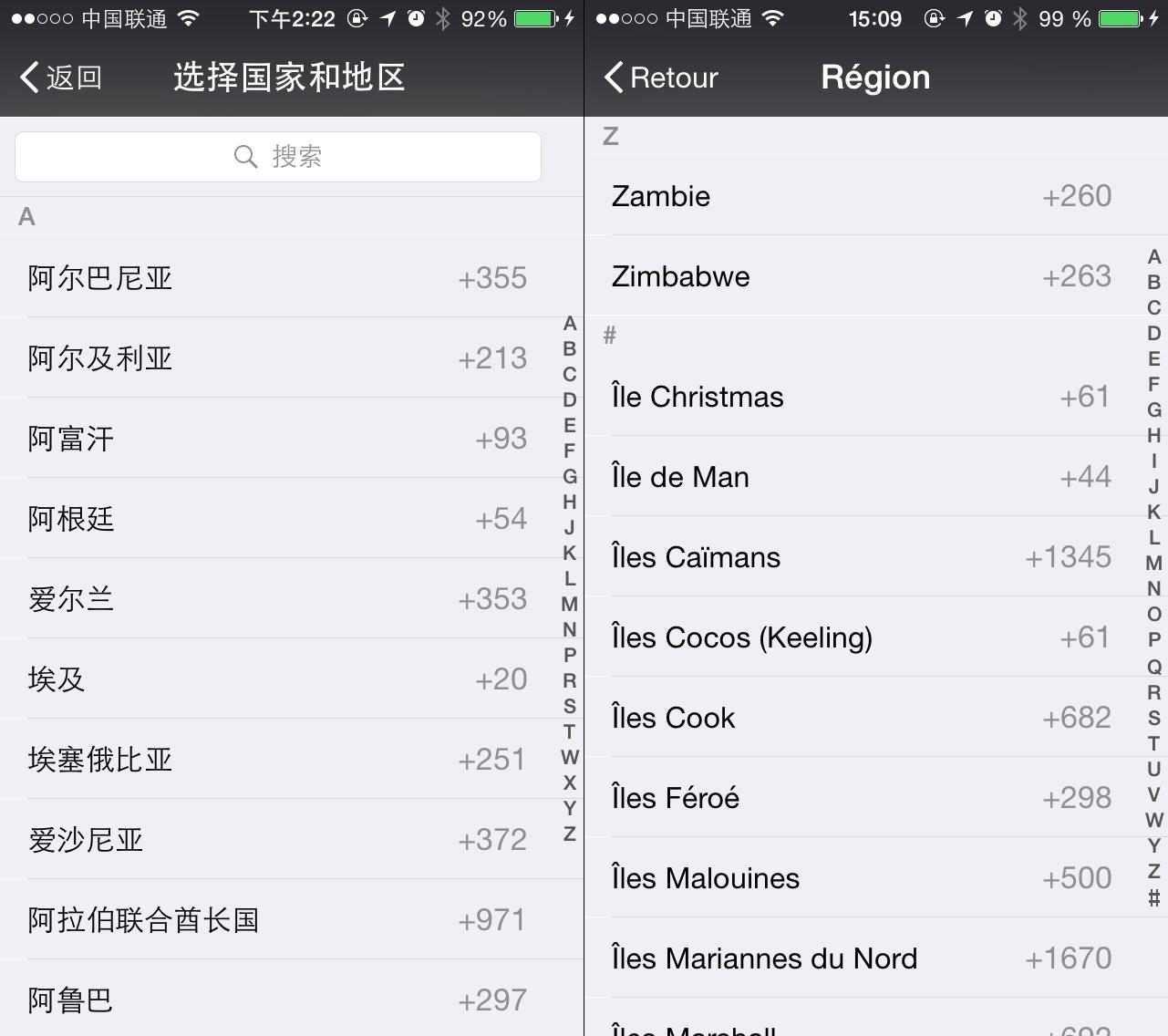
這個(gè)是微信的
? ?
?
微信的問題還是挺多的
- 左邊是中文環(huán)境 按拼音分組是分對(duì)了 但是文字排序卻粗錯(cuò)了 “阿”開頭的國家并沒有排列在一起
- 右邊是法語環(huán)境 這些??衍生拉丁字母?? 并沒有正確的歸類
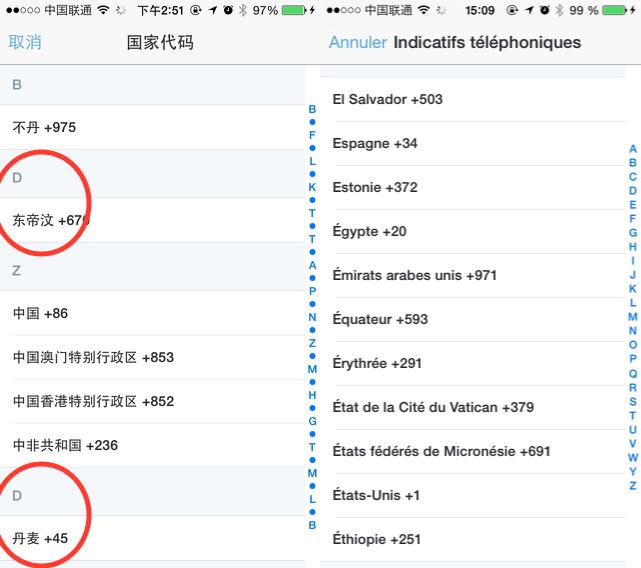
這個(gè)是Twitter的
? ?
?
Twitter在中文環(huán)境下還是挺奇怪的 但是卻沒有犯微信第二個(gè)錯(cuò)誤
Facebook的呢? 人家的工程師比較聰明(懶) 壓根就不支持索引
接下來我們會(huì)解決出現(xiàn)的這幾個(gè)問題
代碼
先簡(jiǎn)歷一個(gè)Modal 用來表示國家相關(guān)的信息
@interface MMCountry : NSObject
@property (nonatomic, strong) NSString *name; //國家名(本地化后的版本)
@property (nonatomic, strong) NSString *code; //國家代號(hào)
@property (nonatomic, strong) NSString *latin; //國家名的拉丁文(只包含基本拉丁字母)
@property (nonatomic, strong) NSString *dial_code; //區(qū)號(hào)
@end
然后我們要把區(qū)號(hào)從配置文件中讀取出來 并以區(qū)號(hào)為key 建立索引
NSData *data = [NSData dataWithContentsOfFile:[[NSBundle mainBundle] pathForResource:@"diallingcode" ofType:@"json"]];
NSError *error = nil;
NSArray *arrayCode = [NSJSONSerialization JSONObjectWithData:data options:0 error:&error];
if ( error ) {
return;
}
//讀取文件
NSMutableDictionary *dicCode = [@{} mutableCopy];
for ( NSDictionary *item in arrayCode )
{
MMCountry *c = [MMCountry new];
c.code = item[@"code"];
c.dial_code = item[@"dial_code"];
[dicCode setObject:c forKey:c.code];
}
接著獲取這些國家的本地話名稱
NSLocale *locale = [NSLocale currentLocale];
NSArray *countryArray = [NSLocale ISOCountryCodes];
NSMutableDictionary *dicCountry = [@{} mutableCopy];
for (NSString *countryCode in countryArray) {
if ( dicCode[countryCode] )
{
MMCountry *c = dicCode[countryCode];
//這里 你懂的
c.name = [locale displayNameForKey:NSLocaleCountryCode value:countryCode];
if ( [c.name isEqualToString:@"臺(tái)灣"] )
{
c.name = @"中國臺(tái)灣";
}
//把名稱拉丁字母化
c.latin = [self latinize:c.name];
[dicCountry setObject:c forKey:c.code];
}
else
{
//找不到則說明配置文件不全 可以補(bǔ)全
NSLog(@"missed %@ %@",[locale displayNameForKey:NSLocaleCountryCode value:countryCode],countryCode);
}
}
這里要注意的是 把字母拉丁文化 解決了微信的第二個(gè)問題 使非基本拉丁字母也可以按照基本拉丁字母來排序 其函數(shù)如下
- (NSString*)latinize:(NSString*)str
{
NSMutableString *source = [str mutableCopy];
CFStringTransform((__bridge CFMutableStringRef)source, NULL, kCFStringTransformToLatin, NO);
//微信是這樣做的
//CFStringTransform((__bridge CFMutableStringRef)source, NULL, kCFStringTransformMandarinLatin, NO);
CFStringTransform((__bridge CFMutableStringRef)source, NULL, kCFStringTransformStripDiacritics, NO);
return source;
}
這里有兩步
- 先將文字 轉(zhuǎn)成拉丁字母(kCFStringTransformToLatin)
- 再將拉丁字母去掉變音符(kCFStringTransformStripDiacritics)
這里是微信犯的***個(gè)錯(cuò)誤 也就是沒有正確歸類的錯(cuò)誤 因?yàn)槲⑿旁?**步的時(shí)候只針對(duì)漢字進(jìn)行了處理 其他字符則沒有處理 導(dǎo)致第二步?jīng)]有得到正確的基本拉丁字符(kCFStringTransformMandarinLatin 參見注釋掉的代碼)
我們來測(cè)試一下這兩步會(huì)造成得到效果 還是之前的例子
NSArray *countryArray = [NSLocale ISOCountryCodes];
NSArray *languageArray = @[@"zh_CN",@"en_US",@"ja_JP"];
for ( NSString *languege in languageArray)
{
NSLocale *locale = [[NSLocale alloc] initWithLocaleIdentifier:languege];
for ( int i = 0 ; i < 5 ; ++i )
{
NSString *countryCode = countryArray[i];
NSString *displayName = [locale displayNameForKey:NSLocaleCountryCode value:countryCode];
NSLog(@"%@\t%@\t%@\t@",languege,countryCode,displayName,[self latinize:displayName]);
}
}
結(jié)果
zh_CN AD 安道爾 | an dao er
zh_CN AE 阿拉伯聯(lián)合酋長(zhǎng)國 | a la bo lian he qiu zhang guo
zh_CN AF 阿富汗 | a fu han
zh_CN AG 安提瓜和巴布達(dá) | an ti gua he ba bu da
zh_CN AI 安圭拉 | an gui la
en_US AD Andorra | Andorra
en_US AE United Arab Emirates | United Arab Emirates
en_US AF Afghanistan | Afghanistan
en_US AG Antigua & Barbuda | Antigua & Barbuda
en_US AI Anguilla | Anguilla
ja_JP AD アンドラ | andora
ja_JP AE アラブ首長(zhǎng)國連邦 | arabu shou zhang guo lian ban
ja_JP AF アフガニスタン | afuganisutan
ja_JP AG アンティグア?バーブーダ | antigua?babuda
ja_JP AI アンギラ | angira
可以到看 系統(tǒng)會(huì)根據(jù)不同國家和不同語言的特點(diǎn) 將同一個(gè)國家的不同表達(dá)形式轉(zhuǎn)化成不同的拉丁字母
接下來 我們把獲取過的數(shù)據(jù)根據(jù)’A’-‘Z’進(jìn)行歸類
NSMutableDictionary *dicSort = [@{} mutableCopy];
for ( MMCountry *c in dicCountry.allValues )
{
NSString *indexKey = @"";
if ( c.latin.length > 0 )
{
indexKey = [[c.latin substringToIndex:1] uppercaseString];
char c = [indexKey characterAtIndex:0];
if ( ( c < 'A') || ( c > 'Z' ) )
{
continue;
}
}
else
{
continue;
}
NSMutableArray *array = dicSort[indexKey];
if ( !array )
{
array = [NSMutableArray array];
dicSort[indexKey] = array;
}
[array addObject:c];
}*** 將每個(gè)歸類下面的數(shù)據(jù) 排序重新整理
for ( NSString *key in dicSort.allKeys )
{
NSArray *array = dicSort[key];
array = [array sortedArrayUsingComparator:^NSComparisonResult(MMCountry *obj1, MMCountry *obj2) {
return [obj1.name localizedStandardCompare:obj2.name];
}];
// array = [array sortedArrayUsingComparator:^NSComparisonResult(CSCountry *obj1, CSCountry *obj2) {
//
// return obj1.latin > obj2.latin;
// }];
dicSort[key] = array;
}
這樣dicSort就是我們最終得到的結(jié)果集
這里是微信犯的第二個(gè)錯(cuò)誤 微信的排序是按照latin來排序的(見注釋掉的代碼) 所以導(dǎo)致了相同漢字的國家排不到一起的情況 正確的方式是用localizedStandardCompare來排序 這也是iOS已為我們提供好了的本地化比較函數(shù)
看看之前的圖中 挑三個(gè)國家出來 比如:阿爾巴尼亞 愛爾蘭 阿魯巴 他們的拼音是 aerbabiya aierlan aluba 如果按照拼音排序的話 這樣的排序就是正確的
我們來看看最終的效果
?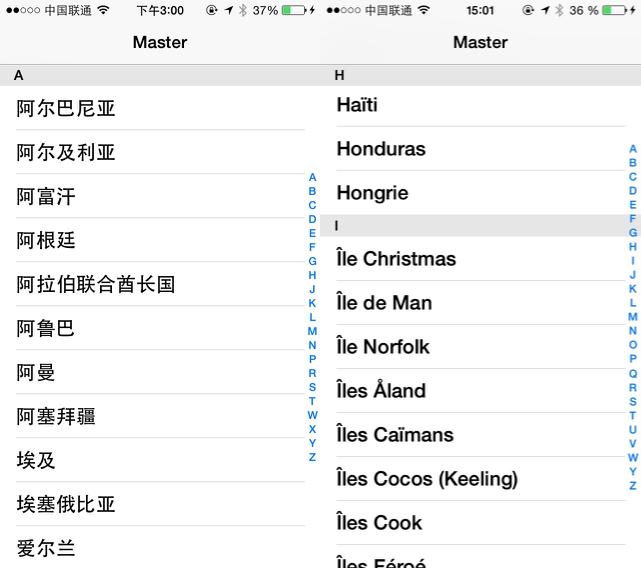 ?
?
是不是比微信的更好?
討論
雖然代碼是寫完了 但是問題并沒有結(jié)果 有一個(gè)關(guān)鍵的問題就是 為什么我們要按照’A’-‘Z’來索引排序呢? 比如Twitter在日文和韓文環(huán)境下是這樣的
?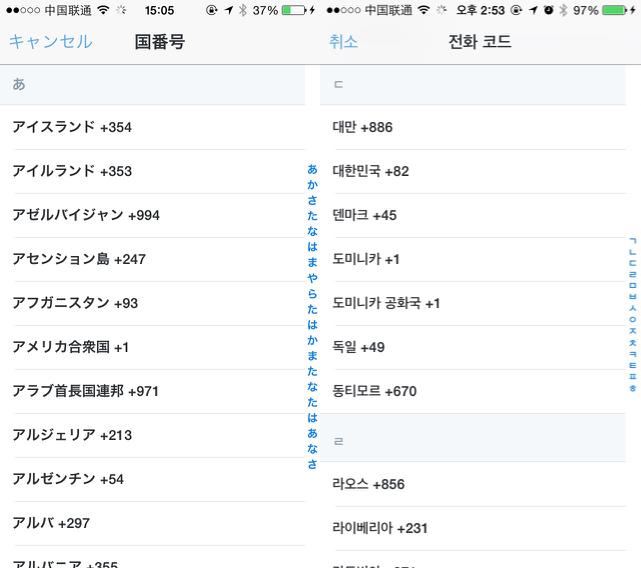 ?
?
其實(shí)按照不同國家的語言特點(diǎn)來進(jìn)行對(duì)應(yīng)的索引 應(yīng)該才是***的解決辦法(PS:看到Twitter在中文環(huán)境下的糟糕結(jié)果 我也不確定其在日文和韓文下的結(jié)果是否是正確的(ˉ﹃ˉ)
當(dāng)然 如果真要這樣做 其實(shí)改動(dòng)量也不大 只要在索引的那塊稍微修改一下就行了
小結(jié)
文中的demo可以在??這里??找到
正如討論中說的一樣 本文所討論的方案 并不是最終的解決方案 如果需要更好的體驗(yàn)的話 還要深入研究各國的文化才行 所以 國際化并不單純是個(gè)技術(shù)問題 更是個(gè)社會(huì)工程啊~~~~